Hello Again.








Today I am going to share a real case study where it is required to execute a stored procedure using Informatica and stores the output of any potential errors.
We have written a stored procedure that will invoke reports from the main frame machine based on inputs, and as a result, a report in the form of PDF will be created. The input for the store procedure will be the report name, which varies. The output, if report name is valid, will be PDF reports that the store procedure invokes, if on the other hand when the report name is not valid anymore, there will be error messages invoked by the store procedure. These error messages along with the date and time will be stored in an database table for reporting purpose.
So having gathered this requirement, how are we going to implement this ETL process in Informatica?
I have decided to create an informatica mapping with stored procedure transformation and use mapping parameters to past report names as inputs to stored procedure transformation. How would the mapping parameters capture the report name values? That is what we will do in DAC which we will get to later.
So let's start with this mapping that I already built:

For the image, I have indicated different parts of the mapping as what they are for. So let's first create a mapping parameter and call it $$ReportNameVar:

In the expression transformation, i have used $$ReportNameVar as an output. In addition, I used the build-in parameter Sys_Date for 'Date' output port and connect it directly to the target table's Sysdate port. The Report Name port is connected to the store procedure transformation to provide its input, it is also connected to the target table's Report Name port to provide the list of report names. Now as I said, the expression for 'Report Name' port in expression transformation is $$ReportNameVar, which is the parameter I just created. We will later work with this in DAC to have it populated with the value we want.

The stored procedure transformation is pretty straight-forward in its configuration, we simply import the store procedure and create the transformation. There are 2 ports upon importing the store procedure: Return_Value as output and return port, P_Report_Name as input port. In the property tab, we can see the name of the store procedure is 'Invoke report':

Now, connect the 'Return_Value' port of the store procedure transformation to 'error_message' port of the target. Connect 'Nextval' from sequence generator to 'Row_ID' of target. Leave 'Error status' unconnected for now, we are all set for the mapping.
I will skip the part on how to create the workflow for this mapping because it is very straightforward. Lets just say that the workflow is MCK_ReportName_SP. Get done and move into DAC.
This is what needs to be done in DAC for this to work:
1. We need to create as many tasks as there is for report names. In our case, we have 7 different reports, so seven tasks needed.
2. In each task, the workflow that it associates to will be the same as 'MCK_ReportName_SP'. But in each task, we create a different parameter value.
3. Group all these tasks in a task group if we are going to index the target table. If not, run them all together in one execution plan.
4. Create a parameter file and save it on the informatica server for DAC to communicate with informatica on passing the values created in step 2.
So first thing first:
All 7 tasks created with the same value for full load commend as 'MCK_ReportName_SP'

Now in the 'parameter' tab under each tasks, we can create parameter and assign values to it. The name of the parameter will be the same as we defined in informatica, and the value will be hardcoded as the report name. Each task will have its own value. In fact, I have made it easier for myself by naming each task with report name as ending:

This is pretty much the configuration. Everything else after that is just straightforward as we group all these 7 tasks in one subject area and create execution plan to run it. If you have trouble understanding how to do it, please read my other articles here.
Don't forget to create parameter files in notepad and save it on the server. In this case, my parameter file is very simple, it only has the following:
[SDE_MCK_Forklift.WF:MCK_ReportName_SP.ST:MCK_ReportName_SP]
$$ReportNameVar = MCKARSV1
SDE_MCK_Forklift is the folder where workflow is saved under in informatica's workflow manager. Then the name of the workflow name and session name are both MCK_ReportName_SP
Now upon running this execution plan, this is what the behavior looks like:

In other words, the same workflow in Informatica will be repeatedly running 7 times one after another's success, because there are 7 tasks all pointing at the same workflow. The only difference is that in the session log of each run, you will see different parameter values being used.
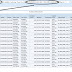
Now let's quickly check the target table 'Report_Status' and see what has been loaded in there:

As we can see, different report name has been loaded with different error messages. The report name column is basically the mapping parameter $$ReportNameVar defined in expression transformation, so this shows that the DAC parameter value has been successfully passed into informatica and loaded into the target..
Error_Message column is using the output 'return_value' of the stored procedure transformation as the source. This shows that the output of the store procedure as been loaded into the target table with different error message defined withe store procedure itself..
So the bottom line is that using parameters defined in DAC, we can pass the value into informatica for running the store procedure. This way of doing is flexible, however, if we are getting more and more reports, then this approach will make you end up with a lot of tasks. If when report name list starts getting longer and longer, we will consider storing these report names in a external table and using that as an input for the store procedure. I digress.
Until next time
Thanks!