What is the difference between complex join and physical join? The easiest way to understand the basic is to remember that physical join is used in Physical layer and complex join is used in BMM layer. However, just knowing that isn't going to be enough to build solid skills on OBIEE development. In order to gain more insight on how it really works in OBIEE, we need to know more about these 2 types of joins.
First, let's look at complex join:
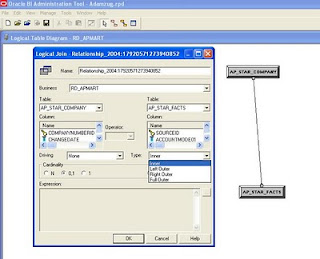
The diagram is a window of a typical complex join. In here, you notice that you can't change any of the table columns of neither logical tables in the join and the expression pane is grayed out. However, you are able to change the type of join from inner to outer joins. This type of behavior is telling us that complex join is a logical join that OBIEE server looks at to determine the relationship between logical tables, in other words, it is just a placeholder. Complex join will not be able to tell the server what physical columns are used in joining, but it will be able to tell the server what type of join this is going to be..
In order to know how exactly the join is, we will need to look at physical join in the physical layer:
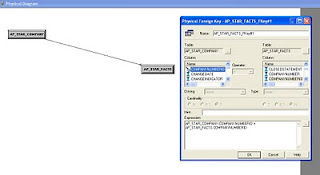
Notice that in this window of physical join, we are able to change the columns under both tables, we are also able to define our own expressions. However, are can't change the joining method unlike complex join. This behavior is to help us to know that this is where we tell OBIEE how to join the 2 actual tables by specifying the columns. Hence this is what physical join does.
Knowing the basic, let's take a step further. Can I use complex join in physical layer or can I use physical join in BMM layer? Yes we can, and by doing it the application will not flag errors. However, we need to know when to use them and what to expect after using them..
Let's look at complex join in physical layer. Although it doesn't happen frequently, it is sometimes needed. Let's say we have 2 tables, promotion fact and contract date dimension. I want to join these 2 tables in such way so that only the dates that are still in contract should return. Therefore, I can't just use a simple join on the date columns from both tables, conditions need to be applied.. In this case, let's use complex join in physical layer:
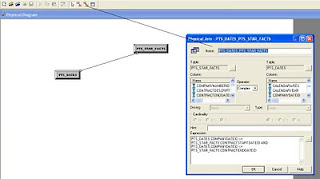
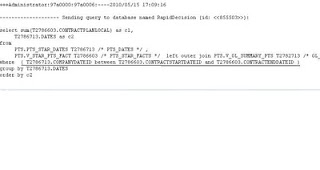
In the below diagram, I enter 'PTS_DATES.COMPANYDATEID >= PTS_STAR_FACTS.CONTRACTSTARTDATEID AND PTS_DATES.COMPANYDATEID <= PTS_STAR_FACTS.CONTRACTENDDATEID' to satisfy the joining condition. At the front end, when you run a report using these tables, this expression will be included in the where clause of the SQL Statement:
Having physical join in BMM layer is also acceptable, however it is very rare to see that happen. The purpose of having physical join in BMM layer is to override the physical join in physical layer. It allows users to define more complex joining logic there than they could using physical join in physical layer, in other words, it works similar to complex join in physical layer. Therefore, if we are already using complex join in physical layer for applying more join conditions, there is no need to follow this set up with physical join in BMM layer again.
Remember, the best data modeling design in OBIEE is not the most complex and overly convoluted design, it should be as straightforward as possible. Therefore, use physical join in physical layer and complex join in BMM layer as much as you can. Only when situation calls for a different join, then go for it.
Til next time
First, let's look at complex join:

The diagram is a window of a typical complex join. In here, you notice that you can't change any of the table columns of neither logical tables in the join and the expression pane is grayed out. However, you are able to change the type of join from inner to outer joins. This type of behavior is telling us that complex join is a logical join that OBIEE server looks at to determine the relationship between logical tables, in other words, it is just a placeholder. Complex join will not be able to tell the server what physical columns are used in joining, but it will be able to tell the server what type of join this is going to be..
In order to know how exactly the join is, we will need to look at physical join in the physical layer:

Notice that in this window of physical join, we are able to change the columns under both tables, we are also able to define our own expressions. However, are can't change the joining method unlike complex join. This behavior is to help us to know that this is where we tell OBIEE how to join the 2 actual tables by specifying the columns. Hence this is what physical join does.
Knowing the basic, let's take a step further. Can I use complex join in physical layer or can I use physical join in BMM layer? Yes we can, and by doing it the application will not flag errors. However, we need to know when to use them and what to expect after using them..
Let's look at complex join in physical layer. Although it doesn't happen frequently, it is sometimes needed. Let's say we have 2 tables, promotion fact and contract date dimension. I want to join these 2 tables in such way so that only the dates that are still in contract should return. Therefore, I can't just use a simple join on the date columns from both tables, conditions need to be applied.. In this case, let's use complex join in physical layer:

In the below diagram, I enter 'PTS_DATES.COMPANYDATEID >= PTS_STAR_FACTS.CONTRACTSTARTDATEID AND PTS_DATES.COMPANYDATEID <= PTS_STAR_FACTS.CONTRACTENDDATEID' to satisfy the joining condition. At the front end, when you run a report using these tables, this expression will be included in the where clause of the SQL Statement:

Having physical join in BMM layer is also acceptable, however it is very rare to see that happen. The purpose of having physical join in BMM layer is to override the physical join in physical layer. It allows users to define more complex joining logic there than they could using physical join in physical layer, in other words, it works similar to complex join in physical layer. Therefore, if we are already using complex join in physical layer for applying more join conditions, there is no need to follow this set up with physical join in BMM layer again.
Remember, the best data modeling design in OBIEE is not the most complex and overly convoluted design, it should be as straightforward as possible. Therefore, use physical join in physical layer and complex join in BMM layer as much as you can. Only when situation calls for a different join, then go for it.
Til next time