Hello
As you have worked in various OBIEE projects, you probably will have encountered different data models for different business. Oracle has implemented their own BI Apps which contains pre-built schema as well. Unless you started the project from ground zero, chances are your project will already have a list of tables created as you walk in to the project. Looking into all these dimensions and facts or cubes, you will probably be told what was going on before and how to move forward from that. However, little did you know the mind of the person who decided on this list of objects nor did you know his understanding of the requirement. You will probably use your technical backgrounds to build the application based on what's already there.
Some of the designs are really good and some of the designs have limitations. Nonetheless, they all come from trials and errors over and over, and the way they are is probably where they concluded to be the most suitable design at the time. So today, I want to just go over something I learned over the years in terms of how to decide the data model based on the understanding of the requirement. This involves a lot of considerations from a holistic perspective.
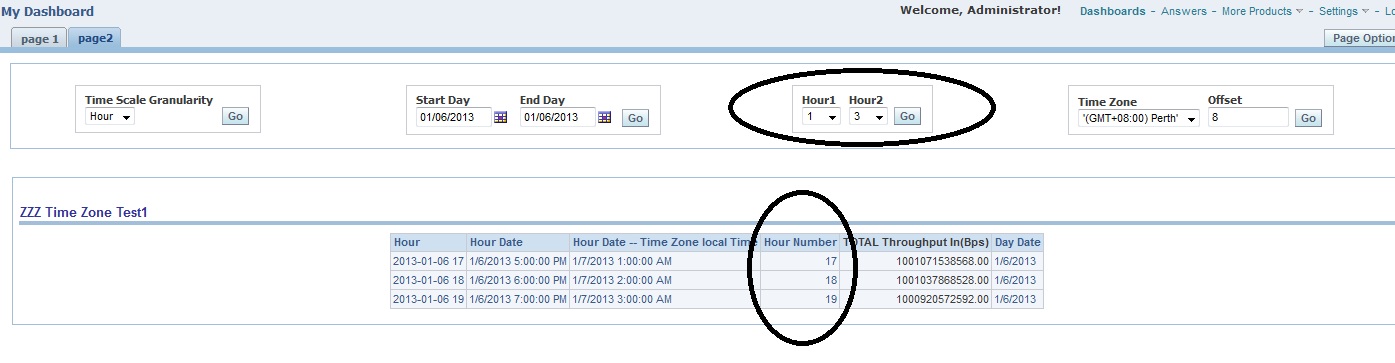
Look at the below diagram:

This is a very simple requirement. I want to create a report that shows me all of the entity As in my system, as well as the entity Bs and Cs that each A associates with at any point in time. I may also want to see the counts of Bs and Cs that each As have.
Simple enough right?
So we have the keys, we create a report that joins all of the these 3 entities. Great, job's done. However, the problem comes when you want to look at the report at a specific time. Why is that a problem?
Well, Lets say entity A doesn't change very often. It could be your local retail branch that once it's opened, it will stay active for a while. Or it could be geographical area or sales territory that won't change unless the business change. Entity B changes more often than A, it may change once a day. So it could be some kind of account status, or in network industry, it could be router or Pseudowire configuration data. And entity C may change hourly, this could be certain business transaction, market indicators or it could be the wireless signals that travels through the area. What if I want to see the information of all my As as well as how many Bs and Cs (in counts) that each As have on Jan 1st 2013 between 3pm to 4pm?
The problem comes that, since all of the As are active, they should be expected to be shown on the list. At this particular hour, not all of the As are associated to any Bs and Cs, their counts should be displayed 0. However, in this particular report, it is not going to happen. Only the As that it's keys are found matching the keys in Bs will return at the particular time, same as for C counts. All of the sudden, users will be scratching their head while looking at this report wondering where are all the other As, because they know they have them in the system..
Let me show you another problem. What if Bs get updated once a day at 12am, then the time key from date dimension will only match when your hour filter is set at 12am for the report to return anything because the time key in your B dimension probably looks like this "201301010000" (for 2013 Jan 1st 12am) and then "201301020000". The only way to query this table without filtering out data is to join B dimension at date level by not looking at the hours. However, what if later on when the business needs to change the data collection frequency from once a day to 4 times a day?
There can be many other issues when it comes to time sensitive information. So knowing all these (trust me, sometimes you wouldn't see the problem unless it hit you, then it could be a big mess!), what should I do?
Seeing that there is a clear hierarchical relationship between these entities (or sometimes there might not be a straightforward hierarchy), we need to find a way to have super set of the data that are pre-computed with all of the entities.
This is where an aggregated fact table should be designed. Imagine there is a table, it is pertaining to entity A, so in this table, all of the As in the system will be preloaded based on it's update frequency. For each As, we will find the associated B keys. Then we have a few columns, like number of Bs, number Cs where the counts of Bs and Cs will be populated hourly. Ideally, you will have each A repeated 24 times per date, on each hours it will show the counts because hour is the granularity of the report. Now you have to be careful, because once you start denormalizing the table, it can result in huge data-sets. We want to really be careful about how many levels of hierarchy you want to report here. Depending on the nature of the business and the data from each entity, only maintain the dimension keys in this table as long as it doesn't expend the data set into too huge volume.
So let's say the nature of the hierarchy is like the following:

In this case, if we put C keys and B keys both into the same aggregate fact table, we might create a huge data set, which we have to be careful about. One option will be breaking this own diagram into smaller areas for reporting.
You can have 1 table that have keys of As and Bs and another for Bs and Cs. In terms of designing the display of the data, you can always go from summary to detail or from high level to lower level. Kind of like the level 1 and level 2 report shown there. This will be a good reference for deciding how many of these pre-computed tables that needs to be create or how to design the granularity of your fact table, it also determines the update frequency of this table.
Oracle has another option for dealing with this kind of requirement, it is called materialized views. Implementing materialized views can provide many benefits, however, it also can come with some drawbacks. Therefore, it needs to be looked at case by case. The idea, though, is similar.
If you look at the BI Apps and many other out of the box schema from OBIEE product, you will see similar things being implemented. There could be many other reasons for that. Knowing the reason, knowing the pros and cons of the data modeling will eventually sets you apart from others who only takes what's been done and run with it.
Thanks, until next time.
As you have worked in various OBIEE projects, you probably will have encountered different data models for different business. Oracle has implemented their own BI Apps which contains pre-built schema as well. Unless you started the project from ground zero, chances are your project will already have a list of tables created as you walk in to the project. Looking into all these dimensions and facts or cubes, you will probably be told what was going on before and how to move forward from that. However, little did you know the mind of the person who decided on this list of objects nor did you know his understanding of the requirement. You will probably use your technical backgrounds to build the application based on what's already there.
Some of the designs are really good and some of the designs have limitations. Nonetheless, they all come from trials and errors over and over, and the way they are is probably where they concluded to be the most suitable design at the time. So today, I want to just go over something I learned over the years in terms of how to decide the data model based on the understanding of the requirement. This involves a lot of considerations from a holistic perspective.
Look at the below diagram:

This is a very simple requirement. I want to create a report that shows me all of the entity As in my system, as well as the entity Bs and Cs that each A associates with at any point in time. I may also want to see the counts of Bs and Cs that each As have.
Simple enough right?
So we have the keys, we create a report that joins all of the these 3 entities. Great, job's done. However, the problem comes when you want to look at the report at a specific time. Why is that a problem?
Well, Lets say entity A doesn't change very often. It could be your local retail branch that once it's opened, it will stay active for a while. Or it could be geographical area or sales territory that won't change unless the business change. Entity B changes more often than A, it may change once a day. So it could be some kind of account status, or in network industry, it could be router or Pseudowire configuration data. And entity C may change hourly, this could be certain business transaction, market indicators or it could be the wireless signals that travels through the area. What if I want to see the information of all my As as well as how many Bs and Cs (in counts) that each As have on Jan 1st 2013 between 3pm to 4pm?
The problem comes that, since all of the As are active, they should be expected to be shown on the list. At this particular hour, not all of the As are associated to any Bs and Cs, their counts should be displayed 0. However, in this particular report, it is not going to happen. Only the As that it's keys are found matching the keys in Bs will return at the particular time, same as for C counts. All of the sudden, users will be scratching their head while looking at this report wondering where are all the other As, because they know they have them in the system..
Let me show you another problem. What if Bs get updated once a day at 12am, then the time key from date dimension will only match when your hour filter is set at 12am for the report to return anything because the time key in your B dimension probably looks like this "201301010000" (for 2013 Jan 1st 12am) and then "201301020000". The only way to query this table without filtering out data is to join B dimension at date level by not looking at the hours. However, what if later on when the business needs to change the data collection frequency from once a day to 4 times a day?
There can be many other issues when it comes to time sensitive information. So knowing all these (trust me, sometimes you wouldn't see the problem unless it hit you, then it could be a big mess!), what should I do?
Seeing that there is a clear hierarchical relationship between these entities (or sometimes there might not be a straightforward hierarchy), we need to find a way to have super set of the data that are pre-computed with all of the entities.
This is where an aggregated fact table should be designed. Imagine there is a table, it is pertaining to entity A, so in this table, all of the As in the system will be preloaded based on it's update frequency. For each As, we will find the associated B keys. Then we have a few columns, like number of Bs, number Cs where the counts of Bs and Cs will be populated hourly. Ideally, you will have each A repeated 24 times per date, on each hours it will show the counts because hour is the granularity of the report. Now you have to be careful, because once you start denormalizing the table, it can result in huge data-sets. We want to really be careful about how many levels of hierarchy you want to report here. Depending on the nature of the business and the data from each entity, only maintain the dimension keys in this table as long as it doesn't expend the data set into too huge volume.
So let's say the nature of the hierarchy is like the following:

In this case, if we put C keys and B keys both into the same aggregate fact table, we might create a huge data set, which we have to be careful about. One option will be breaking this own diagram into smaller areas for reporting.
You can have 1 table that have keys of As and Bs and another for Bs and Cs. In terms of designing the display of the data, you can always go from summary to detail or from high level to lower level. Kind of like the level 1 and level 2 report shown there. This will be a good reference for deciding how many of these pre-computed tables that needs to be create or how to design the granularity of your fact table, it also determines the update frequency of this table.
Oracle has another option for dealing with this kind of requirement, it is called materialized views. Implementing materialized views can provide many benefits, however, it also can come with some drawbacks. Therefore, it needs to be looked at case by case. The idea, though, is similar.
If you look at the BI Apps and many other out of the box schema from OBIEE product, you will see similar things being implemented. There could be many other reasons for that. Knowing the reason, knowing the pros and cons of the data modeling will eventually sets you apart from others who only takes what's been done and run with it.
Thanks, until next time.